Burt.K
Awesome Discovery
코틀린 코루틴 소개
Table of Contents
알림 이 글은 Everything you need to know about kotlin coroutines을 번역한 글임을 알려드립니다.
이 블로그 포스트의 목표는 다양한 코우틴 용어를 숙지하고 다음 질문에 답하는 것입니다.
Job과Deferred,launch와async의 차이점은 무엇인가?- 어떤 코루틴 빌더를 사용해야 하는가?
- 코루틴에서 예외가 발생하면 어떻게 될까?
- 고수준의 구조화 된 동시성을 어떻게 만들 수 있을까?
- 변경 가능한 상태를 싱글스레드 디스패처를 사용해 스레드 안전하게 공유.
- 코루틴을 사용한
IO및CPU바인딩 작업.
코루틴 작동 방식을 이해하고 실제 애플리케이션에서 효과적으로 사용하려면 핵심 개념을 먼저 이해해야 합니다. 이를 위해 다음 주제를 설명합니다.
- 코루틴 스코프 빌더(Coroutine Scope Builders)
- MainScope
- CoroutineScope
- coroutineScope
- GlobalScope, etc.
- 코루틴 컨텍스트(CoroutineContext)
- Job
- Deferred, etc.
- 코루틴 빌더(Coroutine Builders)
- launch
- async
- withContext
- runBlocking, etc.
- 구조를 갖춘 동시성(Structured concurrency)
- 일시 중단(Suspend)
- 연속성(Continuation)
소개
코루틴은 경량 스레드로 코루틴을 만드는 비용은 매우 저렴합니다. 코루틴은 스레드에 비해 매우 빠르게 만들고 파괴되기 때문에 네이티브 OS 스레드에 직접 매핑되지 않습니다. 스레드는 컨텍스트 전환시 추가 오버헤드가 발생하지만 코루틴은 그렇지 않습니다. 그래서 수천, 수만개의 코루틴을 사용할 수 있습니다. 스레드 한 개가 수천개의 코루틴을 운영할 수도 있습니다.
새로운 코루틴을 생성(create), 시작(start), 실행(run)하기 위해서 코루틴 스코프와 코루틴 빌더입니다. 코루틴 생성에 가장 중요한 두 가지 빌딩 블럭입니다.
코루틴 빌더는 새로운 코루틴을 만들 때 사용하고 코루틴 스코프는 코루틴 실행을 위해 필요한 조건을 구성합니다. 예를 들어, 코루틴이 어느 스레드에서 실행될지 구성할 수 있습니다.
스레드와 비교해 보면, 코루틴 빌더는 Runnable 인스턴스를 만드는 팩토리이며 코루틴 스코프는 Java의 ExecutorService 입니다.
그러나 코루틴 스코프는
ExecutorService보다 더 좋습니다.
코루틴이 가볍다는 것을 입증하기 위해서 코루틴 10만개와 스레드 10만개를 만들고 각각 print(".")를 실행하는 예제를 만들어 보겠습니다.
100_000 코루틴
fun main() = runBlocking {
// 100_000개 코루틴을 만들고 "."을 출력합니다.
repeat(100_000) {
launch {
print(".")
}
}
}.......................................................계속됨위의 앱은 크래시 없이 점(.) 100_000개를 출력합니다.
참고 예제에서 사용한 launch 및 runBlocking은 글의 뒷부분에서 자세히 설명합니다. 간략하게 적어보면, runBlocking은 코루틴을 실행하기 위한 환경을 설정하는 것으로 볼 수 있고 launch는 새로운 코루틴을 생성하고 앞서 만든 환경에서 실행되도록 예약하는 코루틴 빌더입니다.
100_000 스레드
fun main() {
// c100_000 threads and print "."
repeat(100_000) {
thread {
print(".")
}
}
}.....................................................계속되다가 Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0 (Thread.java:-2)
at java.lang.Thread.start (Thread.java:714)
at kotlin.concurrent.ThreadsKt.thread (Thread.kt:42)
at kotlin.concurrent.ThreadsKt.thread$default (Thread.kt:25)
at FileKt.main (File.kt:6)
at FileKt.main (File.kt:-1)
Target platform: JVMRunning on kotlin v. 1.3.50위의 앱은
java.lang.OutOfMemoryError: unable to create new native thread예외가 발생하면서 크래시됩니다.
코루틴 스코프 빌더
CoroutineScope는 coroutineContext라는 하나의 추상 속성만 있는 인터페이스입니다.
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}CoroutineScope는 CoroutineContext입니다. 유일한 차이점은 사용 목적입니다. Roman Elizarov는 그의 블로그에서 이에 대해서 자세히 설명하고 있습니다.
기억해야 할 중요한 내용은 새로운 코루틴 스코프가 생성될 때마다 새로운 Job이 생성되어 만들어진 코루틴 스코프와 연관 지어진다는 것입니다.
이 스코프를 사용하여 생성한 모든 코루틴은 이 Job의 자식이 됩니다. 이런 식으로 코루틴 간의 부모-자식 관계가 만들어집니다.
자식 코루틴 중 하나가 처리되지 않은 예외를 던지면 부모 Job이 취소되어 결국 모든 자식 코루틴이 취소됩니다.이것을 구조를 갖춘 동시성이라고 합니다. 이 주제에 대한 자세한 내용은 Notes on structured concurrency, or: Go statement considered harmful 글에 있습니다. 일독을 권장합니다.
CoroutineScope를 만드는 방법
MainScope
MainScope는 UI 컴포넌트를 위한 스코프입니다. MainScope는 SupervisorJob을 생성하고 이 스코프에서 만들어진 모든 코루틴을 Main스레드에서 실행합니다. SupervisorJob을 생성하기 때문에 구조를 갖춘 동시성에서 언급한 것과 달리 하나의 코루틴이 예외를 던지면서 실패해도 다른 코루틴들은 취소되지 않습니다. 자식 코루틴의 실패는 CoroutineExceptionHandler를 사용하여 처리 할 수 있습니다.
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)참고 Main 디스패처를 사용하려면 플랫폼 별로 프로젝트에 추가해야 하는 디펜던시가 서로 다릅니다.
- kotlinx-coroutines-android - 안드로이드 Main 스레드 디스패처
- kotlinx-coroutines-javafx - JavaFx 애플리케이션 스레드 디스패처
- kotlinx-coroutines-swing - Swing EDT 디스패처
CoroutineScope(ctx)
CoroutineScope(ctx) 함수는 제공된 코루틴 컨텍스트(ctx)에서 새로운 코루틴 스코프를 생성합니다. 그리고 생성된 Job을 스코프와 연관 짓습니다.
public fun CoroutineScope(context: CoroutineContext): CoroutineScope = ContextScope(if (context[Job] != null) context else context + Job())다음은 CorotuineScope 만드는 예제입니다. 외부에서 Job을 전달하지 않지만 내부에서 Job을 생성합니다. 구조를 갖춘 동시성을 엿볼 수 있습니다. 자식 코루틴(Child-A)은 100 밀리세컨드 지연 후 예외를 던지기 때문에 다른 자식 코루틴(Child-B)는 첫 println()문을 실행한뒤 대기하다가 취소됩니다.
val scope = CoroutineScope(CoroutineName("Parent"))
// New job gets created if not provided explicitely
if (scope.coroutineContext[Job] != null) {
println("New job is created!")
}
scope.launch {
launch(CoroutineName("Child-A")) {
delay(100)
println("${Thread.currentThread().name} throwing exception")
throw MyException
}
launch(CoroutineName("Child-B")) {
println("${Thread.currentThread().name} before exception...")
delay(500)
println("${Thread.currentThread().name} after exception...")
}
}New job is created!
DefaultDispatcher-worker-2 @Child-B#3 before exception...
DefaultDispatcher-worker-1 @Child-A#2 throwing exception
Exception in thread "DefaultDispatcher-worker-2 @Child-B#3" MyException: Dummy exceptioncoroutineScope(block)
이 함수는 일시 중단 함수(suspending function)입니다. 코루틴 스코프를 생성하면서 새로운 Job을 만들고 일시 중단 된 블럭을 이 스코프에서 호출합니다. 이 함수는 외부 스코프에서 코루틴 스코프를 상속하고 컨텍스트의 Job을 재정의합니다.
기억할 점은 이 함수가 일시 중단 함수라는 것과 join 및 await을 하지 않아도 주어진 블럭과 스코프의 모든 자식 코루틴이 실행을 완료하면 반환된다는 것입니다.
public suspend fun <R> coroutineScope(block: suspend CoroutineScope.() -> R): R예를 들어, 여러개의 비동기 작업이 있고 모든 작업이 완료되고 결과가 나올 때까지 대기한 다음 어떤 일을 수행해야 한다고 생각해 봅시다.
이 경우 coroutineScope를 사용하여 모든 작업을 동시에 병렬로 시작하고 결과를 기다릴 수 있습니다.
// simulate some compute sensitive task
suspend fun task1(): Int {
delay(100)
return 10
}
// simulate some compute sensitive task
suspend fun task2(): Int {
delay(200)
return 20
}
// 1. performs tasks parallely
// 2. waits for all tasks to finish
// 3. usage computed results of all tasks and returns addition of those
suspend fun doTask() = coroutineScope {
val result1 = async { task1() }
val result2 = async { task2() }
result1.await() + result2.await()
}
println(doTask())출력 결과
30GlobalScope
GlobalScope는 싱글톤입니다. 그 어떤 Job에도 연결되어 있지 않습니다.
GlobalScope는 최상위 레벨에서 코루틴을 시작합니다. 그렇기 때문에 구조화 된 동시성에서 얻을 수 있는 모든 이점이 사라집니다. GlobalScope는 되도록이면 사용하지 않는 것이 좋습니다.
public object GlobalScope : CoroutineScope {
override val coroutineContext: CoroutineContext get() = EmptyCoroutineContext
}다음 블로그 글은 GlobalScope를 사용하지 말아야 하는 이유를 설명하고 있습니다.
The reason to avoid GlobalScope
다음은 GlobalScope에 연결된 Job이 없음을 보여주는 예입니다. GlobalScope를 사용하는 코루틴에서 예외를 발생해도 다른 코루틴에 영향을 미치지 않습니다. 구조를 갖춘 동시성을 느슨하게 한다는 것을 알 수 있습니다.
val job = GlobalScope.coroutineContext[Job]
if (job == null) {
println("No Job associated with GlobalScope!")
}
// exception thrown in this coroutine does not affect other coroutines
GlobalScope.launch {
delay(500)
println("throwing exception")
throw MyException
}
GlobalScope.launch {
println("before exception...")
delay(1000)
println("after exception...")
}출력 결과
No Job associated with GlobalScope!
before exception...
throwing exception
Exception in thread "DefaultDispatcher-worker-2 @coroutine#1" MyException: Dummy exception
after exception...CoroutineContext
CoroutineContext는 키(Key)와 엘리먼트(Element)를 연결하는 간단한 map입니다.
- 키 -
CoroutineContext타입인 엘러먼트를 위한 키 - 엘리먼트 -
CoroutineContext의 하위 타입. 예를 들어, Job, Deferred, CoroutineDispacher, ActorCoroutine 등.
문제
변경 가능한 상태가 있습니다. 서로 다른 코루틴에서 동시에 접근할 수 있을 때, 우리는 이 상태를 스레드로부터 안전하게 만들려고 합니다. 어떻게 하는게 좋을까요?
이를 달성하는 여러 가지 방법이 있지만 이 글에서는 싱글스레드 실행 서비스(single-threaded executor service)를 사용하는 방법을 보여 드리겠습니다.
다음은 1000개의 코루틴이 동시에 생성되고 각 코루틴이 카운터 값을 증가시키는 예제입니다. 실행 결과로 1000이 나오면 이 풀이 방법에 경쟁 조건(race condition)이 없음을 증명하는 것입니다.
incrementAsync 함수에서 스레드 이름을 출력하여 모든 코루틴이 동일한 스레드에서 실행되는 것을 직접 확인할 수 있습니다.
// 1. create single threaded dispacher
val ec: ExecutorService = Executors.newSingleThreadExecutor()
val dispatcher: ExecutorCoroutineDispatcher = ec.asCoroutineDispatcher()
// 2. bind coroutine scope with single threaded dispatcher
val scope = CoroutineScope(dispatcher)
var counter = 0
val jobs = mutableListOf<Job>()
fun incrementAsync() = scope.launch { counter += 1 }
// 3. launch 1000 coroutines to increment counter
repeat(1000) {
jobs += incrementAsync()
}
// 4. wait for all the coroutines to finish
jobs.joinAll()
println("Counter = $counter")출력 결과
Counter = 1000Job과 구조를 갖춘 동시성
백그라운드 Job은 side-effect를 단독으로 담당하는 Job입니다. 개념적으로 Job은 취소할 수 있는 것이며 생명주기와 연결되어 있습니다.
코루틴은 Job 인터페이스를 구현하여 코루틴의 생명주기를 관리합니다. Job은 부모-자식 관계를 갖도록 설계되어 있어 구조를 갖춘 동시성을 실현하는데 큰 도움이 됩니다.
A, B, C라는 3개의 Job이 있다고 생각 해 봅시다. Job B와 C는 Job A의 자식입니다.
예를 들어, Job C가 CancellationException 이외의 예외를 던지고 실패하면 상위 Job A는 알림을 받습니다. 이 경우 A는 다른 자식 Job(이 경우에는 B)에게 즉시 종료 알림을 보냅니다. 이렇게 하여 구조를 갖춘 동시성이 만들어집니다.
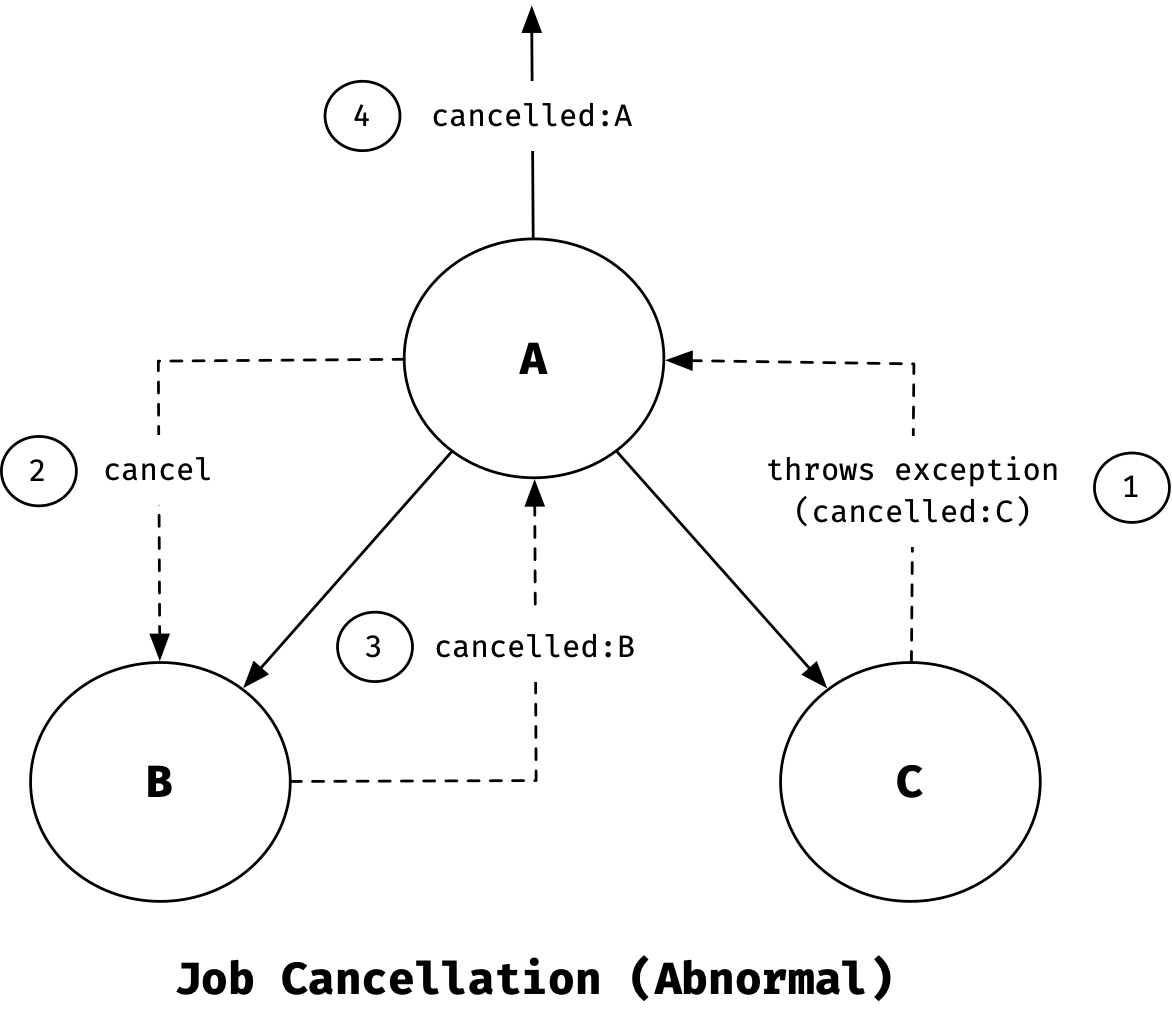
참고 취소 원인이 CancellationExcpetion인 경우, 정상적으로 취소된 것으로 간주되기 때문에 이 경우 부모 Job은 다른 자식 Job에게 종료 알림을 보낼 필요가 없습니다.
부모-자식 관계는 서로 다음과 같은 영향을 미칩니다.
cancel또는 예외로 인한 완료(즉, 실패)로 부모가 취소되면 모든 자식이 즉시 취소됩니다.- 부모는 모든 자식이 완료 될 때까지 완료 할 수 없습니다.
- 부모는 모든 자식이
완료또는취소상태로 완료 될 때까지 기다립니다. - 자식에서 catch하여 처리하지 않은 예외는 부모를 취소합니다. 특히,
launch,CoroutineScope.launch코루틴 빌더로 생성한 자식 코루틴에 적용됩니다. async,CoroutineScope.async및 future와 비슷한 다른 코루틴 빌더는 캐치되지 않는 예외가 없음을 기억해야 합니다. 모든 예외가 catch되어 결과에 캡슐화 되기 때문입니다.
Deferred
문서에서 지연된 값(Deferred value)을 차단되지 않는(non-blocking) 취소 가능한 Future로 결과를 가지고 있는 Job으로 설명하고 있습니다.
Deferred는 완료된 결과를 successful 또는 exceptional 로 얻을 수 있게 Job에 몇가지 메서드를 추가한 인터페이스입니다.
코루틴 빌더(Coroutine Builders)
다양한 요구 사항에 따라 코루틴을 만들 수 있는 여러 가지 방법이 있습니다. 이 섹션에서 그중 몇 가지를 살펴보겠습니다.
가장 일반적으로 사용되는 두 가지 코루틴 빌더는 launch와 async입니다.
이들은 CoroutineScope의 확장으로 코루틴 스코프가 있어야 새로운 코루틴을 생성할 수 있습니다.
Launch
launch는 새로운 코루틴을 만들고 코루틴에 대한 레퍼런스를 Job으로 반환합니다. 이 핸들을 사용하면 Job에서 사용 가능한 cancel 메서드를 사용하여 시작된 코루틴을 개발자가 직접 취소 할 수 있습니다.
launch는 비동기 작업을 수행하지만 결과에는 관심이 없는 경우에 주로 사용합니다.
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): JobAsync
async는 새로운 코루틴을 만들고 코루틴에 대한 레퍼런스를 Deferred로 반환합니다. 이 핸들을 사용하면 Deferred에서 사용 가능한 cancel 메서드를 사용하여 시작된 코루틴을 개발자가 직접 취소 할 수 있습니다.
async는 미래의 계산 결과가 예상되는 비동기 작업을 실행할 때 사용합니다. 결과를 얻게 되면, 이 결과를 사용하여 다른 작업을 수행합니다.
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>이러한 구성을 사용하여 코루틴을 실행하면 새로운 Job이 생성된다는 점을 반드시 기억해야 합니다. 현재 코루틴이 실행된 부모 Job과 코루틴 컨텍스트를 상속합니다. 새로 생성된 Job은 자식 노드로 부모에 연결됩니다.
다음은 launch와 async의 기본 동작입니다.
- 코루틴 시작(start)는 즉시 실행됩니다.
- 코루틴을 시작할 때 다른 CoroutineStart 매개변수를 전달하여 이 동작을 재정의 할 수 있습니다. 예를 들어,
start = CoroutineStart.LAZY를 줄 수 있습니다. - 코루틴에서 예외가 발생하면 컨텐스트 내에서 부모 Job이 취소되고 다른 모든 자식 코루틴이 취소됩니다.
- CoroutineScope를 생성할 때 명시적인 SupervisorJob을 재공하여 이 동작을 재정의 할 수 있지만 이 내용은 이 글에서 다루지 않겠습니다.
- 코루틴은 Default CoroutineDispatcher에서 실행됩니다. 이것은 스레드 공유 풀에 의해 유지되며, 최대 스레드 수는 CPU 코어 갯수(최소 2개)와 같습니다. 어떤 IO 작업을 수행한다고 예를 들면,
context = Dispatchers.IO와 같은 커스텀 CoroutineContext를 전달하여 이 동작을 재정의할 수 있습니다.
withContext
CPU와 IO에 모두 바인딩 된 작업을 수행하려는 경우가 많습니다. 이 때, CPU 바운드(스레드 = CPU 코어 수)와 다른 스레드 풀(경우에 따라서는 언 바운드)에서 IO 바운드 작업을 수행하는 것이 매우 중요합니다. Thread Pools라는 글에서 이러한 분리가 필요한 이유에 대한 자세한 내용을 확인할 수 있습니다.
withContext 문법은 이러한 목적으로 설계되었습니다. 다음은 withContext를 사용하는 방법을 보여주는 예제입니다.
// 1. create new coroutine scope with default dispatcher
val scope = CoroutineScope(Dispatchers.Default)
scope.launch {
// 2. do some cpu bound operations, runs on Default thread pool
println("${Thread.currentThread().name} doing CPU work...")
// 3. shifts to IO thread pool
withContext(Dispatchers.IO) {
// 4. do some io operations like file read, network calls etc
println("${Thread.currentThread().name} doing IO work...")
}
// 5. shifts back to Default thread pool
println("${Thread.currentThread().name} back to doing CPU work...")
}실행 결과
DefaultDispatcher-worker-1 @coroutine#1 doing CPU work...
DefaultDispatcher-worker-1 @coroutine#1 doing IO work...
DefaultDispatcher-worker-2 @coroutine#1 back to doing CPU work...위 예제에서 withContext는 새로운 컨텍스트에서 Dispatcher를 사용합니다. 새로운 디스패처가 지정된 경우, 블럭의 실생을 다른 스레드로 이동하고 완료되면 원래의 디스패처로 다시 되돌아옵니다.
출력의 처음 두 줄을 보면 모두 동일한 스레드에서 실행되었지만 세 번째 줄은 다른 스레드에서 실행되었습니다. 이것은 IO 디스패처가 Default 디스패처와 스레드를 공유하기 때문에 withContext(Dispatchers.IO)를 사용해도 실제로 다른 스레드로 전환되지 않고 동일한 스레드에서 실행이 계속됩니다. 이렇게 하면 스레드 전환 비용을 없앨 수 있습니다. 그러나 해당 스레드는 IO 스레드로 표시되고 스레드 풀에서 제거됩니다. 그렇기 때문에 세 번째 출력문은 다른 스레드에서 실행된 것입니다.
========= Output =======
DefaultDispatcher-worker-1 @coroutine#1 doing CPU work…
DefaultDispatcher-worker-1 @coroutine#1 doing IO work…
DefaultDispatcher-worker-2 @coroutine#1 back to doing CPU work…runBlocking
runBlocking의 유즈케이스는 매우 한정되어 있어 사용을 권장하지 않습니다. runBlocking이 여러분 문제의 마지막 해결이며, 여러분이 무엇을 하고 있는지 정확히 알고 있는 경우에만 사용해야 합니다.
runBlocking은 새로운 코루틴을 시작하고 코루틴이 완료될 때까지 현재 스레드를 차단합니다. 일시 중단 및 논블록킹 스타일로 작성된 일반 블록 코드와 라이브러리를 연결하도록 설계되었습니다. 유즈케이스는 매우 한정되어 있습니다. 예를 들면,
- 메인 애플리케이션을 차단하기 위해서
runBlocking을 사용할 수 있습니다. 메인 애플리케이션에서 실행 된 모든 코루틴이 정상적으로 또는 비정상적으로 완료 될 때까지 메인 애플리케이션이 종료되지 않도록runBlocking을 사용하여 차단할 수 있습니다. runBlocking은 테스트에 매우 유용합니다.runBlocking에 테스트를 담을 수 있습니다. 이렇게 하면 테스트 코드가 동일한 스레드에서 순차적으로 실행되고 모든 코루틴이 완료 될 때까지 종료되지 않습니다. 명시적으로 코루틴을join또는await할 필요가 없습니다. 테스트는 동기화 코드의 테스트와 비슷합니다. 다음은 비동기 및 논블록 스타일로 작성한incrment함수를 테스트하는 예제입니다.incrment는counter를 1씩 증가시킵니다. 테스트는 카운터를 증가할 수 있어야 합니다.incrment함수를 50번 호출하고counter == 50으로assert합니다.// ==== SUT: System Under Test ==== var counter = 0 suspend fun incrment() { delay(10) counter += 1 } // ================================ @Test fun `should able to increment counter`() = runBlocking { repeat(50) { incrment() } println("counter = $counter") assert(counter == 50) { "Assertion failed, expected=50 but actual=$counter" } }
출력 결과
counter = 50자세한 내용은 이 글을 참고합니다.
Suspend
이 글에서 suspend 키워드를 이미 여러 번 사용했습니다. 일시 중단 함수를 자세히 살펴봅니다!
suspend는 kotlin 키워드로, 함수를 일시 중단했다가 나중에 재시작할 수 있음을 나타냅니다. 일시 중단 함수를 사용하여 메인스레드를 차단하지 않고 장시간 실행되는 계산을 호출 할 수 있습니다.
일시 중단 함수 호출 규칙:
- 다른 일시 중단 함수에서 호출할 수 있습니다.
- 코루틴에서 호출할 수 있습니다. 일시 중단 함수가 호출된 코루틴에서 코루틴 컨텍스트를 상속합니다.
Kotlin 코드는 JVM 바이트 코드로 변환됩니다. JVM에는 일시 중지인 suspend 키워드의 개념이 없습니다. 내부에서 Kotlin 컴파일러는 일시 중단 함수(suspend function)를 suspend 키워드 없는 다른 함수로 변환합니다. 이 함수는 함수 콜백인 Continuation을 추가 매개변수로 받습니다.
다음은 Kotlin의 일시 중단 함수와 JVM으로 컴파일된 함수를 보여주는 예제입니다.
// kotlin
suspend fun updateUserInfo(
name: String,
id: Long
): User
// JVM
public final Object updateUserInfo(
String name,
long id,
Continuation<User> $completion
)Continuation
Continuation은 Kotlin 표준 라이브러리에 정의 된 간단한 인터페이스입니다. resumeWith(result)메서드만 정의하고 있습니다.
public interface Continuation<in T> {
public val context: CoroutineContext
public fun resumeWith(result: Result<T>)
}
참고v1.3부터Continuation에는 1개의resumeWith(result)메서드만 있습니다. 이전 버전에서는usedresume(value: T)와resumeWithException(exception: Throwable)가 있었습니다.Result는 T타입 값으로
success또는 Throwable타입 예외로failure를 모델링합니다.
참고 Result 모나드에 대한 내용은 모나드와 함수형 아키텍처 글을 참고합니다.
Result를 사용하여 onSuccess와 onFailure 같은 메서드가 있는 콜백 스타일의 프로그래밍과 잘 연결할 수 있습니다.
이 모든 것이 내부에서 어떻게 작동하는지 알고 싶다면 Roman Elizarov talk — Deep Dive into Coroutines. 영상을 보는 것이 좋습니다.
이 강연에서 Roman Elizarov는 다음과 같이 말했습니다.
Continuation은 제네릭 콜백 인터페이스입니다.
일시 중단 함수를 호출할 때마다 실제로 콜백을 호출합니다. 콜백은 암시적이므로 코드에 표시되지 않습니다. 배후에서 콜백을 사용하여 멋진 스타일로 바로 코딩할 수 있습니다.